Anche voi in preda alla disperazione dopo aver letto dell’incompatibilità tra Xhtml 2 e le versioni precedenti? Suvvia, fate i bravi. Sedetevi e calmatevi, ragioniamo con calma.
Probabilmente provate un misto di paura e rabbia, come è successo a Mark Pilgrim, e credete di avere gettato nella pattumiera tutto il lavoro che vi ha portato a realizzare pagine valide, aderenti agli standard, addirittura accessibili.
Questo è possibile, ma se succederà, non è colpa degli standard che evolvono. Dispiace dirlo, ma la colpa sarà probabilmente solo vostra.
Non fatevi ingannare dalle etichette
E’ meglio che vi facciate da subito il callo quando lavorate con gli standard: le vostre pagine Xhtml 1.x valide, magari che usano i Css per il layout, vivranno meno di quello che pensate.
Probabilmente non vi aspettavate che questo standard fosse messo quasi subito in discussione (e in effetti non è così). La verità è che oggi non riusciamo ad immaginare come l’Xhtml evolverà nei prossimi anni e quali cambiamenti introdurrà nel modo di concepire una pagina web.
Una soluzione per dormire sonni tranquilli esiste, e non richiede nessun tipo di tecnologia di ultima generazione: è in realtà un approccio mentale.
I vantaggi di X(ht)ml
Il primo passo consiste nell’adottare lo standard Xhtml per la costruzione delle pagine.
Perché preferire Xhtml a Html? Tra tutti i pregi, sicuramente il fatto che un documento Xhtml è anche un particolare tipo di documento Xml.
E qual è il vantaggio di Xml? Perché preoccuparsi di questo standard a prima vista esoterico? Con Xml potete definire accuratamente i dati e la struttura delle informazioni della realtà in esame (un libro, un listino prodotti, ecc.). Non solo: avete la possibilità di trasformare agevolmente un documento Xml per ottenere risultati molto diversi (una pagina web, un file di testo, un documento Pdf, un altro documento Xml). Per farlo si utilizzano le trasformazioni Xsl (Xslt), un linguaggio decisamente potente che è possibile imparare e addomesticare in poco tempo.
La facilità con cui si realizza una trasformazione è proporzionale alla qualità con cui è stato descritto il documento X(ht)ml.
Quindi, fintantoché realizzate dei buoni documenti Xhtml, non avete nulla da temere: potrete sempre, se lo volete, trasformare una versione nella successiva e viceversa.
Il problema è un altro: cos’è che fa di un documento Xhtml un “buon” documento Xhtml?
Ad ogni oggetto il suo nome
Appartenete a quel genere di sviluppatori che posti di fronte ad un template grafico cominciano ad immaginare tabelle, Css, regole e tag (un po’ come succedeva a Russel Crowe in A Beautiful Mind quando cercava indizi sui giornali)? Non solo siete pronti per il manicomio, probabilmente state anche sbagliando l’approccio di lavoro.
La fase di codifica della pagina, quella in cui decidete le parti in cui dividere il layout e iniziare la stesura del codice, non è il primo problema di cui preoccuparsi.
Dovete invece chiedervi: “quanti e quali sono gli oggetti che posizionerò nella pagina?“, una domanda che a prima vista suona banale. Attenzione però: non stiamo parlando di oggetti che corrispondono ad elementi dell’Xhtml. La risposta, cioè, non è “posiziono tre tabelle, una con il menù, una con il corpo centrale e una con un piè di pagina”, ma qualcosa del tipo “inserisco un menù contestuale, una lista di libri, la top ten dei più venduti”.
Perché preoccuparsi di questa fase? Perché l’unica arma a vostra disposizione per evitare l’obsolescenza delle pagine non è una corsa sfrenata agli standard di ultima generazione, ma la cura della struttura e del contenuto della pagina che state creando.
Se raggiungete un buon livello di dettaglio nel descrivere gli elementi che compongono il vostro sito sarete facilitati nell’usare il markup, e riuscirete a traghettare il significato della pagina alle future versioni degli standard.
Un piccolo e concreto esempio
Per entrare nel concreto, non è necessario ricorrere ad esempi di siti complessi. Immaginate allora di dover realizzare una semplice pagina Html che contenga un elenco di libri. Come pensate di procedere?
Il signor Rossi
Il signor Rossi sa che è importante realizzare pagine valide: da un po’ di tempo lo dicono tutti. Non ne ha però ancora capito bene il motivo. “Intanto – pensa – realizzo codice Xhtml valido. Così facendo il mio sito non invecchierà tanto facilmente”.
Un estratto della pagina realizzata da Rossi è il seguente:
1 <table>
2 <tr>
3 <td width=”20%”><img src=”immagine.gif” alt=”” /></td>
4 <td width=”80%” align=”left”>Libro 1</td>
5 </tr>
6 <tr>
7 <td colspan=”2″>Cum e Cilicia decedens Rhodum venissem et eo mihi de Q. Hortensi morte esset adlatum opinione omnium maiorem animo cepi dolorem. nam et amico amisso cum consuetudine iucunda tum multorum officiorum coniunctione me privatum videbam et interitu talis auguris dignitatem nostri conlegi deminutam dolebam</td>
8 </tr>
9 <tr>
10 <td colspan=”2″>Prezzo: 16 euro<br />Casa editrice: Domus</td>
11 </tr>
12 </table>
Il codice è indubbiamente valido (ci mancherebbe), ma privo di struttura e significato. Sono state usate delle tabelle non solo per contenere i dati, ma anche per presentarli visivamente. E’ sbagliato anche il ricorso al tag br per separare su più linee elementi dal significato diverso.
Il signor Verdi
Il signor Verdi sorride mentre osserva il lavoro del signor Rossi. “Poveretto – pensa – non ha ancora capito che queste cose si costruiscono ricorrendo ai fogli di stile”.
Sicuro di quello che fa, propone una soluzione che utilizza i Css:
1 <div class=”librosx”>
2 <img src=”immagine.gif” alt=”” />
3 <div class=”titoloblu”>Libro 1</div>
4 <div class=”txtnormal”>Cum e Cilicia decedens Rhodum venissem et eo mihi de Q. Hortensi morte esset adlatum opinione omnium maiorem animo cepi dolorem. nam et amico amisso cum consuetudine iucunda tum multorum officiorum coniunctione me privatum videbam et interitu talis auguris dignitatem nostri conlegi deminutam dolebam</div>
5 <div>Prezzo: 16 euro<br />Casa editrice: Domus</div>
6 </div>
Lasciate stare il risultato visivo della pagina, che non è paragonabile (e non serve che lo sia) a quello precedente. Non ci interessa neppure analizzare quello che contiene il foglio di stile.
Anche se non considerariamo questi elementi, possiamo ugualmente dire che la situazione, rispetto a prima, è migliorata, ma solo di poco.
I problemi principali sono fondamentalmente due:
- Il signor Verdi è convinto di usare i fogli di stile per separare la forma dal contenuto. E allora cosa ci fanno nomi di classi come librosx (libro a sinistra) e titoloblu? Cosa succede se un domani il libro va posizionato a destra, oppure il titolo diventa verde? Dobbiamo intervenire su tutte le pagine, o ci accontentiamo di una classe titoloblu che in realtà rende il testo verde?
- Gli oggetti della pagina non sono stati etichettati con coerenza, tanto che non è facile distinguere gli elementi che la compongono. Txtnormal non dà sufficienti informazioni, sommario sarebbe stata la scelta corretta
Cercate anche di evitare facili nomi come header e footer: concentratevi su quello che contengono, non sull’uso che ne fate nel layout di pagina.
Ricordate: l’adozione dei fogli di stile quale unico strumento per comandare il layout di pagina non è una questione di moda o di immagine: non siete più bravi solo perché realizzate siti senza tabelle. La forza dei Css non è infatti quella di eliminare l’uso di elementi nati per altri scopi, ma più in generale di consentire una netta separazione tra i contenuti e la resa visiva. Sta sempre a voi scegliere il modo corretto di applicarli.
Come fare
Cercate di sforzarvi per capire quali e quanti elementi state posizionando sulla pagina. Chiamate le regole dei Css in modo che sia chiaro e univoco a quali oggetti si riferiscono. Non abbiate paura ad utilizzare due regole che producono lo stesso identico risultato, ma che si applicano ad oggetti diversi: domani possono cambiare.
Una possibile, semplice soluzione, è la seguente:
1 <div class=”libro”>
2 <img src=”libro1.gif” alt=”” />
3 <h1 class=”libroTitolo”>Libro 1</h1>
4 <p class=”libroSommario”>Cum e Cilicia decedens Rhodum venissem et eo mihi de Q. Hortensi morte esset adlatum opinione omnium maiorem animo cepi dolorem. nam et amico amisso cum consuetudine iucunda tum multorum officiorum coniunctione me privatum videbam et interitu talis auguris dignitatem nostri conlegi deminutam dolebam</p>
5 <p>Prezzo: <span class=”libroPrezzo”>16 euro</span></p>
6 <p>Casa editrice: <span class=”libroEditore”>Domus</span></p>
7 </div>
Come vedete, apparentemente è cambiato ben poco. In realtà il significato della pagina ora è chiaro, non ambiguo e soprattutto coerente.
L’uso del tag div è stato ridotto allo stretto necessario, poiché si tratta di un contenitore di oggetti. Abbiamo premiato il titolo del libro, utilizzando un header h1. Tra i tanti vantaggi, uno screen reader è in grado di scorrere agevolmente queste intestazioni.
Anche il nome delle regole nel Css è più chiaro, e rispecchia gli elementi del libro.
Il contenuto la fa da padrone
Perché fare questo? Se prendete la buona abitudine di organizzare il contenuto della pagina in questo modo, un domani, quando dovete aggiornare il sito alla nuova versione di Xhtml, questa operazione sarà enormemente facilitata. Non solo: potrete riutilizzare il contenuto in scenari e ambiti diversi, al solo costo di una trasformazione.
Pensate ad un caso banale, un menù di navigazione. La versione 8 di Xhtml potrebbe prevedere, per questo tipo di menù, il tag <mn>. Poniamo il caso che oggi lo abbiate realizzato in Xhtml nella forma <div class=”menu”><span class=”menuVoce”>Voce 1</span><span class=”menuVoce”>Voce n</span></div>. Poiché la pagina è semanticamente ricca e coerente, non avrete problemi a trasformare (proprio utilizzando un banale foglio Xslt) questa versione nella successiva. (Potreste anche farlo con un trova/sostituisci, ma non sempre questa operazione risulta praticabile efficamente.)
Cosa fare invece se la prossima versione di Xhtml non consente più di utilizzare il tag acronym (come effettivamente sarà): che fare?
Potreste decidere, con una trasformazione, di cambiare ogni acronym in un tag abbr, visto che questa è la soluzione consigliata dalla specifiche. Attenzione però: state calcando una strada di non ritorno. Mentre è possibile passare da un documento ricco di markup ad uno con un ridotto numero di tag e attributi, il viceversa non è evidentemente possibile.
Per questo motivo, il consiglio è di preservare quanto più possibile la semantica del documento originario. Invece di passare da acronym a abbr, ad esempio, potreste valutare la possibilità di inserire qualche attributo di aiuto, che vi aiuti a capire quello che una volta era un tag acronym. Una soluzione potrebbe essere quella di usare una classe dei fogli stile (ad esempio class=”acronym”), oppure di impiegare un elemento neutro, come uno span (<abbr title=”File Transfer Protocol”><span class=”acronym”>Ftp</span></abbr>).
Fatevi aiutare da chi sa
Come vedete, l’idea per rinvigorire il vostro codice è semplice: cercare di descrivere con un buon livello di dettaglio il contenuto della pagina.
Non è però affatto facile individuare e descrivere gli oggetti che utilizzerete nel sito, come non lo è la valutazione dell’efficacia di una soluzione rispetto ad un’altra. Potreste trovarvi, un domani, a recriminare sull’opportunità di alcune vostre scelte.
Ma avete diverse fonti da cui attingere prima di tuffarvi nel difficile compito di modellare la realtà su una pagina web.
Se il sito per il quale realizzerete i template si basa su un database per la generazione delle pagine, potreste coinvolgere uno sviluppatore e chiedere che vi illustri il diagramma entità/relazione delle tabelle.
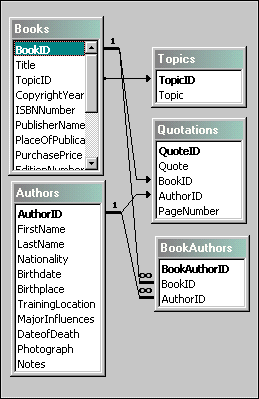
Non è nostra intenzione entrare nel dettaglio di queste tecniche, ma è facile intuire come la struttura del database trovi un riflesso negli elementi della pagina Html. Se il database ha una tabella Libri, con i campi Titolo e Pagine, è molto probabile che anche la vostra pagina si comporti allo stesso modo. Cercate di capire quanto più possibile quello che avete a disposizione per descrivere gli oggetti del sito.
Da dove cominciare
Css, codice valido, Xml, Xsl, semantica, database…costruire una pagina web richiede molte competenze variegate.
Da dove partire? Meglio abbandonare subito le tabelle ed immergersi a capofitto nello studio dei fogli di stile? Non proprio.
Il vostro obiettivo principale è realizzare pagine valide, possibilmente utilizzando lo standard Xhtml (quale versione, lasciamo a voi scegliere).
A questo punto cercate di convertire una vostra pagina in una pagina che descriva correttamente gli oggetti che rappresenta, ricorrendo ad un modesto uso dei Css. E’ senza dubbio meglio se già li conoscete a fondo, ma anche se continuate ad usare tabelle per il layout può andare bene ugualmente all’inizio. Anzi, piuttosto di applicarli come il signor Verdi nell’esempio precedente, concentratevi sugli oggetti e per il momento lasciate perdere il layout via Css.
Solo quando avete capito come descrivere una pagina potete affrontare l’uso avanzato dei fogli di stile.
E infine, per far quadrare il cerchio, dovreste cominciare ad affrontare le trasformazioni Xsl, scegliendo uno dei manuali consigliati nelle nostre recensioni.
Probabilmente non donerete al sito il segreto dell’eterna giovinezza, ma se non altro gli garantirete una felice vecchiaia.






{kind=link}